


I dati sintetici vengono utilizzati per formare modelli di intelligenza artificiale in grado di analizzare dati tabulati, come le informazioni finanziarie.Credito: Kazuhiro Nogi/AFP/Getty
Non è nemmeno oltre gennaio e il 2025 si sta già dimostrando un anno determinante per l’intelligenza artificiale (AI). Il 21 gennaio, solo un giorno nella sua presidenza, il presidente degli Stati Uniti Donald Trump ha annunciato lo Stargate Project, una joint venture tra le principali società tecnologiche e finanziatori negli Stati Uniti, in Giappone e negli Emirati Arabi Uniti. Hanno promesso 500 miliardi di dollari per lo sviluppo di infrastrutture di intelligenza artificiale negli Stati Uniti.
Eppure solo il giorno successivo, Deepseek, un’azienda di ricerca AI con sede a Hangzhou, in Cina, ha dimostrato che potrebbero non essere necessarie somme così vaste. Ha rilasciato DeepSeek-R1, un modello linguistico di grandi dimensioni (LLM) in grado di compiti passo-passo analoghi al ragionamento umano-secondo quanto riferito a una frazione del costo e della potenza di calcolo degli LLM esistenti. Nei primi test, le sue prestazioni sui compiti in chimica e matematica corrispondono a quella dell’O1 LLM pubblicata lo scorso settembre da Openai, una società con sede a San Francisco, in California. La notizia di un’intelligenza artificiale economica ma avanzata ha inviato il prezzo di alcuni titoli tecnologici in una coda.
Lo strumento AI che può interpretare immediatamente qualsiasi foglio di calcolo
Tra le varie visioni per l’IA che probabilmente definiranno i prossimi anni, importanti studi continueranno a essere pubblicati, ma non tutti faranno notizia. Anche loro devono essere ascoltati, discussi e discussi. Uno di questi lavori è stato pubblicato in Natura All’inizio di questo mese. Si chiama “previsioni accurate su piccoli dati con un modello di fondazione tabulare” (N. Hollman et al. Natura 637319–326; 2025), e potrebbe essere rivoluzionario per il campo della scienza dei dati, secondo uno dei suoi revisori, Duncan McElfresh, ingegnere di dati presso la Stanford Health Care di Palo Alto, in California, scrivendo in un articolo di accompagnamento di notizie e visualizzazioni (DC McElfresheshresh Natura 637274–275; 2025).
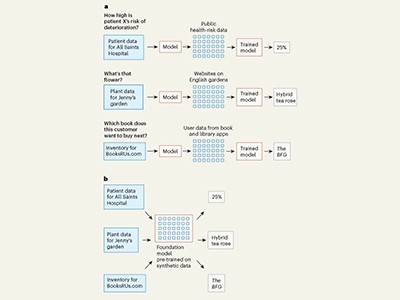
Gli LLM più noti sono pre-addestrati su centinaia di miliardi di esempi di dati effettivi, come testo e immagini. Ciò consente loro di rispondere alle domande degli utenti con un grado di affidabilità. Ma cosa succede se i dati rilevanti del mondo reale non esistano nelle quantità richieste? L’intelligenza artificiale può ancora fornire risposte affidabili se addestrata su un minor numero di set di dati? Questa è una domanda chiave per i ricercatori che usano l’IA per fare previsioni da set di dati tabulati, di cui non vi è nulla vicino alla quantità richiesta per la formazione dei modelli AI. IL Natura Lo studio suggerisce che si potrebbero ottenere risultati affidabili se i modelli AI sono addestrati su “dati sintetici”-dati generati casualmente che imitano le proprietà statistiche dei dati del mondo reale.
Questo progresso è opera degli informatici Noah Hollman, Samuel Müller e Frank Hutter all’Università di Friburg, in Germania e ai loro colleghi. Il loro modello è chiamato tabpfn ed è progettato per analizzare i dati tabulati, come quelli che si trovano nei fogli di calcolo. In genere, un utente crea un foglio di calcolo popolando righe e colonne con dati e utilizza modelli matematici per fare inferenze o proiezioni da tali dati. Tabpfn può fare previsioni su qualsiasi piccolo set di dati, che vanno da quelli utilizzati nella contabilità e nella finanza a quelli della genomica e delle neuroscienze. Inoltre, le previsioni del modello sono accurate anche se sono formate interamente senza dati del mondo reale, ma invece su 100 milioni di set di dati generati casualmente.

Le aziende di intelligenza artificiale devono giocare in modo equo quando usano i dati accademici in formazione
I dati sintetici non sono liberi da rischi, come il pericolo di produrre risultati imprecisi o allucinazioni. Questo è in parte il motivo per cui è importante che tali studi vengano replicati. La replica, una pietra miliare della scienza, rassicura anche gli utenti che possono fidarsi dei risultati delle loro domande.
Migliorare la fiducia nell’intelligenza artificiale, insieme a ridurre al minimo i danni, deve rimanere una priorità globale, anche se sembra essere stata declassata da Trump. Il Presidente ha annullato un ordine esecutivo dal suo predecessore, che ha invitato il National Institutes of Standards and Technology (NIST) e le società di intelligenza artificiale a collaborare per migliorare sia la fiducia che la sicurezza dell’IA, anche per l’uso di dati sintetici. Il nuovo ordine esecutivo di Trump, che si chiama “rimozione di barriere alla leadership americana nell’intelligenza artificiale”, trascura di usare la parola “sicurezza”. Lo scorso novembre, NIST ha pubblicato un rapporto sui metodi per l’autenticazione dei contenuti di intelligenza artificiale e il monitoraggio della sua provenienza (vedi go.nature.com/42c21tn). I ricercatori dovrebbero basarsi su questi sforzi e non lasciarli perdere.
Il lavoro di Hollman e dei colleghi è un esempio di necessità che stimola l’innovazione: i ricercatori hanno capito che non c’erano abbastanza set di dati del mondo reale accessibili per addestrare il loro modello e quindi hanno trovato un approccio alternativo.
Rimane il caso che tutti i modelli di intelligenza artificiale, addestrati su dati sintetici o nel mondo reale, siano ancora scatole nere: utenti e regolatori non sappiano come viene raggiunto un risultato. Quindi, poiché il 2025 porta sviluppi più entusiasmanti, non dimentichiamo gli studi che tentano di comprendere il “come e perché” dell’IA e anche i documenti dei metodi. Sono importanti quanto le pubblicazioni che annunciano le scoperte.



{kind=link}